The Records Project (A Study of Paper vs. Computers)
One of my interests is finding efficient and useful ways to create, store, and retrieve information. I've tried tools ranging from wikis to to-do list managers to databases to Evernote to electronic notebooks to binders and paper notebooks, and while I continue to use a small fraction of those tools, still the grass is always greener on the other side, and I’m continually trying new ones.
When I recently started my biggest project to date, though, I knew that success required tools that would work and that would keep working, and, to my surprise, I’ve found those tools. This isn’t to say that they have not changed and been added to and removed from and modified, but their core has remained, and the project has remained workable, useful, and interesting to me – unlike nearly every other system I’ve used for more than a few months (I’m coming up on a year and nine months now). Because it’s been such a success, I think there are some important lessons to be learned from the project, and I would like to share the general idea.
Paper vs. Computers
When people talk about how to store and access information in the Information Age, the first and often most divisive question is whether it should be accessed through one or more computers or printed on sheets of dead tree. The debates inevitably come down to the same arguments over and over: Computers let you access information more efficiently, computers are the wave of the future, computers are faster to work with, computers let you back up your information. But then computers can crash, and paper is easier to read and work with, makes it easier to include information that’s more complicated than letters of the Latin alphabet, and doesn’t require you to have a charged battery. I’m sure you could supply a few more sound bites if you were called upon to do so. Nobody ever seems to win these arguments, although both sides are usually quite sure they’re right.
The debate is often portrayed as a battle between the enlightened people who understand technology and will carry the torch into the future and the technophobes who stick to paper because they’re scared or ignorant of technology or don’t want to give up what they’re used to, who hang on desperately to the relics of a bygone age and have been seduced by some foolish notion of emotional attachment to having paper in their hands. If this is the narrative you’re used to, the answer you read on the website titled The Technical Geekery might surprise you.
My answer, actually, is that we’ve built a false dichotomy for ourselves. There is no reason why a system needs to be limited to one medium, or why a system should be limited to one medium, except for lack of imagination, laziness, and the kind of technological elitism described above. At best, the people developing email systems, word processors, and databases implement a “print” function while looking down their noses at users who still want to take the antiquated and environmentally irresponsible action of printing out a document. So much more is possible! There is no reason why a system analogous to hypertext cannot be implemented on paper, except for the fact that almost nobody does it (the rare specimens of paper encyclopedias that remain being one of the few exceptions). There is no reason why we cannot have electronic searching and eBook copies of our printed documents, except for the way the book industry has developed. There is no reason why part of a system cannot be part on paper and part electronic (and I don’t mean that your book includes a CD-ROM containing ugly, buggy, and worthless software that works only on a specific type of computer and was thrown together at the last minute and shoved into the back of the book along with a prominent note on the front cover that you’re making a good purchase because it comes with a FREE CD!). And there is no reason why a combined system like this cannot exchange information in both directions as it develops. These ideas are what I’ve explored – to great success – in my project.
The Records Project
This project is called the Records Project. It’s a surprisingly slippery concept to define, so I’ll describe it simply: the core idea of the project is that I sit down and write about my life every day. That might end up being three lines on a sheet of paper that very briefly sketch the important events of the day, or it might end up being several thousand words of exposition or exploration or ranting. It all depends on the amount of time I have and my mood and what happened during the day. (Incidentally, I think this flexibility is key to the success of the method: some days there just isn’t the time or interest to do anything more than three lines on a sheet of paper, but making that an acceptable entry has ensured that I haven’t given up on the project.)
There are two places where I write things in the Records Project, and I’ll look at each of them in turn.
Random Thoughts
The first is called Random Thoughts, and it’s a document that’s been evolving since 2009. In this document I put quotations, anecdotes, ideas, and notes to myself; I add things if and when I feel like it. It’s kept in two text files on my computer; one is an archive and the other contains the current year’s notes. In order to be able to reference things in the document, the entries are numbered sequentially. Using some custom Linux Magic™, if I know I want to go to, say, entry 3456, I can call up the Random Thoughts window (which I always keep open on my laptop), type ;ta 3456, and the program figures out which file and what line that entry begins on and brings me there.
The power of that system starts to become apparent when you consider that, after more than 4500 ideas that run through your mind enough to make worth recording, you start building off of ideas you’ve had previously and it’s nice to keep track of how they link together. If, when I’m writing a new entry or when I’m reading old ones, I’m reminded of something else, I do a search of the document to find the other entry, and I link them together by simply writing the number of each next to the other. Thereafter, if I’m reading one and want to see the other, I can position my cursor over the number and press Ctrl-] to go look at the other entry.
(A section that you can skip over if you want, for those interested in the theory of linking: My links go both ways, a method known (creatively enough) as bidirectional linking. Most of us are used to unidirectional links because that’s what we have on the Web, but in many cases the connection is equally valid and interesting in both directions. The main reason many systems don’t use them is that it’s more difficult to maintain: you have to go place a link at the other end, and in a system like the World Wide Web, you probably don’t have permission to write a link onto somebody else’s web server. Since this is all my system, the only issue is the effort, and I’m committed to the better links it produces, so I write “BL” (for Backlink) and the source at every location I link to, even when this means going to the shelf and grabbing another notebook when it wouldn’t otherwise have been necessary.
The stories of other pioneering hypertext systems and some people’s insistence on bidirectional links on the Web are fascinating; take a look at this, for instance.)
Here’s an example page of Random Thoughts (click to enlarge):
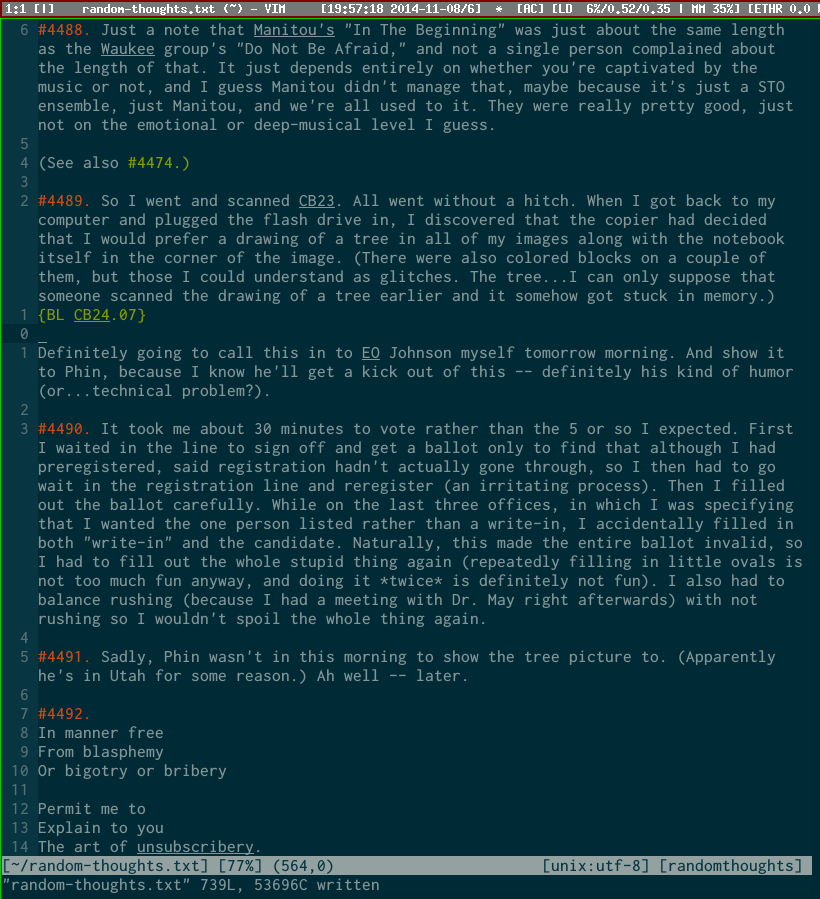
CBs
CB stands for Chrono Book, a name chosen because once upon a time I had many other types of notebooks titled “something book.” My CBs are 80-page Moleskine Cahier notebooks; there’s nothing magical about that type of notebook, but I like them, they’re likely to be around for a while, and sticking with the same ones makes things nice and consistent. I’m on my twenty-fourth one at the moment. I make sure to write an entry in it every evening, but beyond that there are no requirements about the content or length. (Occasionally, if I don’t have time to treat the events of the day properly, I will put the entry off until the next day and just make some brief notes before going to bed.)
Here’s what a typical page looks like:

Searching CBs
The paper-is-for-Luddites camp will point at me here and say, “Hah! But how do you find anything in your 2000 pages of paper notes?” Believe me, I thought about this before I started – and while I admit that I do not have full-text search and that that can sometimes be a liability, I can still find things remarkably well. The heart of the system is an index of each notebook, which I maintain in the front cover of each notebook as I write, adding to it after I finish each day’s entry. When I finish the notebook, I type all of the index entries into the Records Project Paper Augmentation System (RPPAS).
The RPPAS is a custom software package that I wrote from scratch; here is where being highly computer-literate comes in handy. I took a long, hard look at how long it was going to take and other possibilities for handling the task, but found that there was no other software that even remotely resembled what I wanted. The RPPAS is still in development, but all the essential features that I need work.
The software runs in a terminal (a text-based interface) because it’s easy to program and efficient to use. It looks like this:
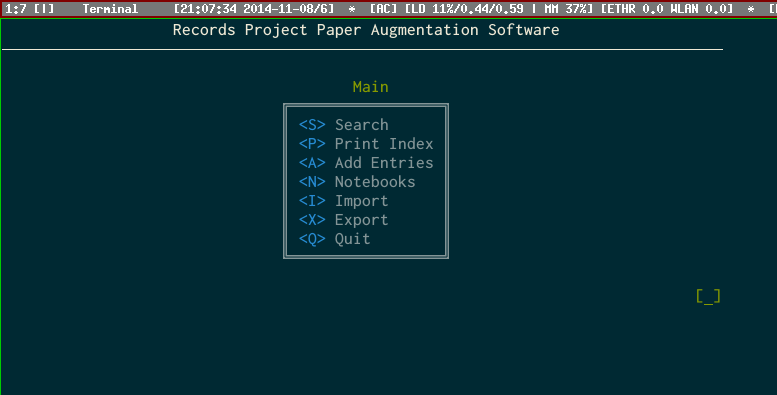
With the RPPAS, I can search all of my indexes at once for keywords I’ve put in the index. Once the results are displayed, I can press the number next to it to see what notebooks and pages that keyword is used at. Here’s an example for the keyword “Technical Geekery”:
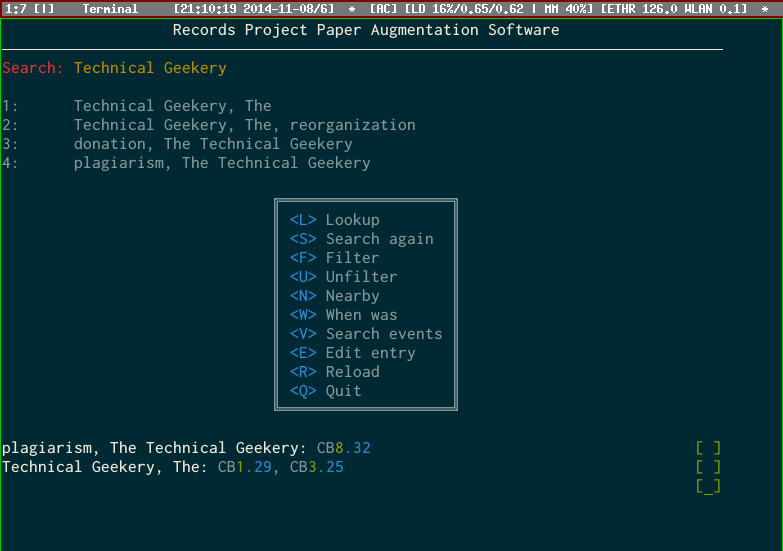
If there are a number of locations listed for the same keyword, it can be pretty tough to figure out which one used the keyword in the way you were thinking of. Since index entries are really just a concise way of describing the content of the page, I wrote the “nearby” query to quickly list other index entries around a given one. For instance, in the following screenshot, I can easily learn that the rather vague entry “gender” listed in CB14 was about a discussion we had in my sociology class about whether the concept of gender should exist in society, as well as the “unpopular opinion” that arose as part of the discussion:
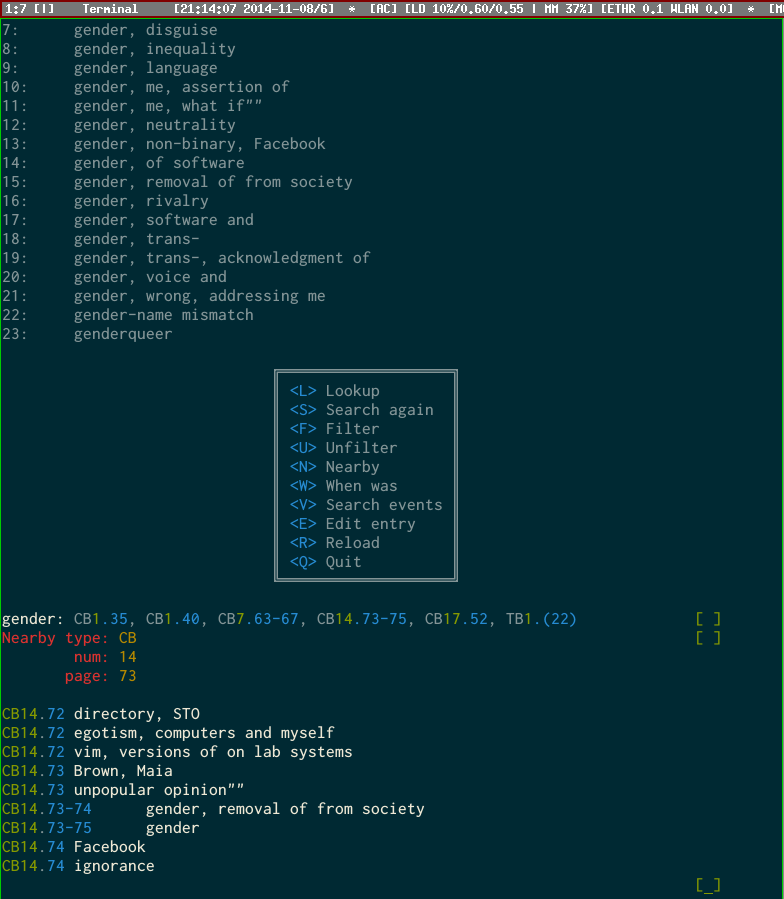
I happen to remember offhand that “CB14” began during the end of the Interim term of my freshman year, but that’s not something I can count on for all the notebooks I have, especially as I continue to add more. So if I don’t remember when the events in CB14 actually were, I can use the aptly named “When was” query, which shows the dates as well as the events listing, a list I put in the front cover of each notebook listing the most salient events:
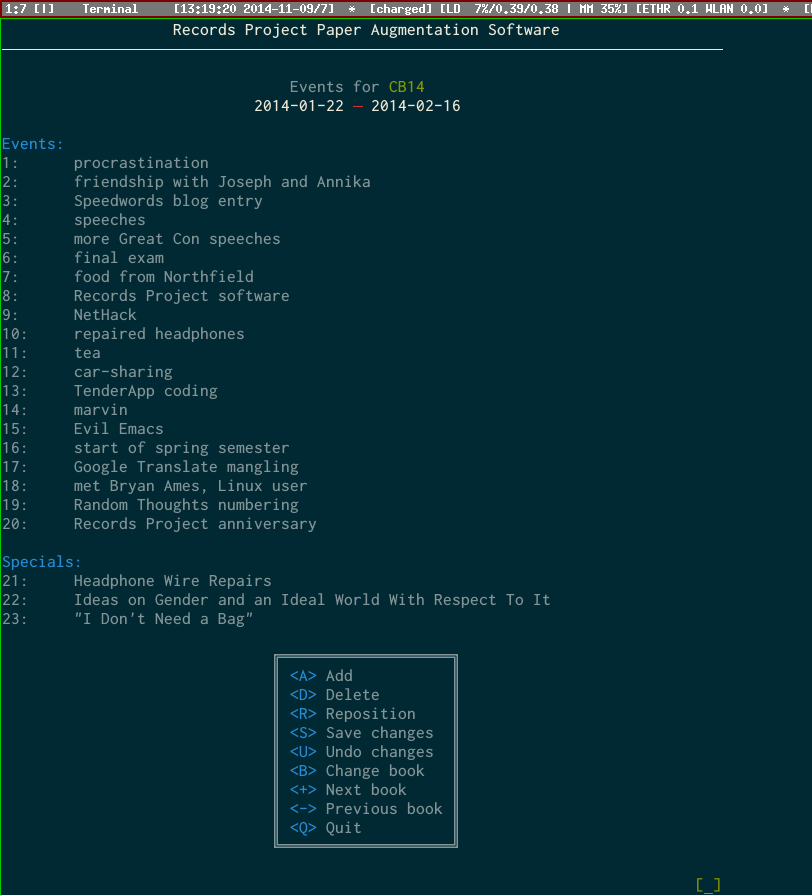
This system allows me to find most things in about thirty seconds of searching at the computer. The downside of indexing as opposed to the full-text search possible on a computer file is that I might neglect to add a certain keyword or have not thought about the relevance of that keyword to the text at the time when I wrote it, and I would then be unable to find it by searching that keyword in the index. Even on the occasions where this happens, information is rarely lost forever; I can often remember a related concept which is in the index and find it that way.
It is foolish but common to assume that full-text search is intrinsically superior to paper-based search methods like indexing. Full-text search can be defeated as well; I recently couldn’t find the list of classes I intended to take next semester in my Random Thoughts document, even though I was certain that I’d written them in there. After manually paging through the document scanning for it, I found that I’d described them as “courses” rather than “classes,” causing the search to miss it. Full-text search, when used for large documents, also has an unfortunate tendency to find all sorts of things that are not actually relevant (unless you remember the exact wording that was used), forcing you to wade through piles of irrelevant information. Since index entries are assigned manually, they only get attached to things that you consider important, and you can use the same wording in the index for related pieces of information that don’t actually share a keyword in the text.
(Before you ask, Google succeeds in providing useful full-text searches of the unimaginably massive amount of data on the Internet using an extremely complex algorithm which draws on all kinds of metadata provided by sites (including index-like keywords!), the number of links to each page, what other users have looked at, the user’s personal search habits, and God knows what else; any system smaller than Google simply does not have the data or the computational resources to make that a useful approach.)
Exchange between Mediums
At the end of my discussion of paper and computers, I alluded to the idea that my definition of a good paper-computer hybrid system includes exchange of information in both directions. I have three ways of doing this (besides the already-described searching mechanism).
First, in addition to references within CBs and Random Thoughts, I use references between the two. Often I want to quote something I wrote in Random Thoughts in CB, or I want to allude to an event or experience from CB in something I write in Random Thoughts. So I simply write “RT 2412” in my CB or “CB20.56” (volume 20, page 56) in the Random Thoughts entry. If I want to look up the Random Thoughts entry, I go to the computer and type ;ta 2412 into my Random Thoughts window; if I want more information on the event, I can do some poking around in the RPPAS with that reference, or I can go to the closet and grab the notebook. There is really no disconnect between the electronic and paper components.
Second, I scan all of my completed paper notebooks into the computer, thereby addressing another of the anti-paper objections, that I might lose the notebook, drop it into the water, or have my house burn down. The scans are high-quality enough that I could reprint them or use them as a substitute for the paper notebooks if necessary, although I’d still much rather have the originals.
Finally, I occasionally print out a copy of the index, which I can use if I don’t have a computer handy and which will itself provide a backup to the computer version. (I do back up my files, but you never know for sure what might happen.) I’m a typography nerd, so I spent some time creating a feature that uses the LaTeX engine to create a nice, compact index (PDF, as an image at legible quality would be huge).
Why?
I know there’s probably one more burning question for many readers: why go to all this bother? This might be a question of why I want to use the hybrid paper/computer system, or why I’m doing this project at all. These are valid questions, and I’ll take them in turn.
Paper is a different medium than a computer. And because of this, I write differently on paper than I write on my computer. In particular, after many years of hard work and practice, I’m an extremely fast and natural typist (it’s a bad day that I type at less than 100 WPM in complete comfort). In my simple form of handwritten shorthand I can reach about 50WPM when I’m giving myself writer’s cramp while frantically scrawling scribbles that I might be able to read back in five minutes. Typing would mean that I could write more; for a while I kept a journal on the computer, and I think I did write more words than I do now. But for CBs I like writing slower, taking a few more minutes to reflect and really think about the words I’m writing instead of mashing them out on the keyboard.
Call me weird, but I also like writing by hand, and it’s something I don’t get a lot of chances to do nowadays, so paper gives me that chance. As I said before, I tried keeping a journal on the computer for a while, and I was inconsistent with that because I didn’t enjoy it; it always felt like a chore. I wanted to have a record of what I was doing and my thoughts, but I didn’t want to write it, and that’s as much a recipe for failure as trying to become a professional musician when you can’t stand practicing your instrument. Writing by hand with my fountain pen and my notebooks and going through the ritual of numbering and indexing makes it less of a task. Occasionally writing does feel like a task in this system, but only rarely, usually when I have something on my mind and resent having to take the time to do anything else at all.
That’s why the project has succeeded with paper, and why I don’t think it would have succeeded on the computer. It would also be a tremendous, unsearchable mess if I hadn’t developed the computerized indexing system and moved all of my random notes into the computerized Random Thoughts. This is why the combination is the solution.
But why do it in the first place? There are plenty of reasons, but a couple stand out. I initially started the project because I wanted to improve my autobiographical memory, and that has certainly happened. I’m sure that it has also made me a better writer, even in the relatively short timespan of the project. I’ve written over 450,000 words in RT and CB combined, and even when I’m not trying to produce polished writing, writing that many words cannot help but improve your writing skills. And often I do look something up in the thesaurus or spend some time working out how to express a complex idea. Finally, it satisfies my desire to have a complicated, organized system of information that is truly useful, and I get to play with information systems while accomplishing something.
Should you try something like this? It would be silly to say there is a right answer to this question. But a Random Thoughts–like document takes practically no effort and can be both lots of fun and extremely useful. All you have to do to start is create a new document in your word processor or text editor of choice and start typing whenever you have something you want to write down. That can be quotations, stories from your day, reminders about things you need to do, anything you want. Sure, there are tools that will make it easier to use (for instance, I have macros that will jump between files, find numbered references, and automatically insert the next unused number for a new entry), but you don’t need them to get started.
My CB system is for the truly dedicated. I have not left out an entry for a single day so far, and I don’t intend to. Regardless of how picky you are about that, it takes time and deliberate effort to write something regularly, and most people will give up (including me, until I found this system). It also takes additional time and motivation to maintain the search system so that you can find things. I think it’s worth it, but everyone will not, and we would live in a boring world if everyone did.
That said, I highly recommend a project of this kind (if at a lower level of commitment), even if you only try it for a couple of weeks and conclude it's not for you. And trust me, it gets easier: once you're past the first couple of months, it changes from being a difficult project you're working on to something you just do.
If you’re interested in the RPPAS software I described earlier, my code and a manual can be found on GitHub, licensed under the GNU General Public License.